The Double-Ellipsoid Geometry of CLIP
ICML 2025


 ArXiv
ArXiv
 Demo
Demo
Abstract
Contrastive Language–Image Pre-Training (CLIP) is instrumental across many domains, yet its embedding geometry is not fully understood. We examine the raw (pre-normalized) features and show that image and text reside on linearly separable ellipsoid shells, both shifted away from the origin. We explain the benefits of this structure and introduce a notion of conformity, which closely matches cosine similarity to the modality mean. We further connect this geometry to the modality gap and the narrow-cone effect.

Key Insights
Double-Ellipsoid Geometry
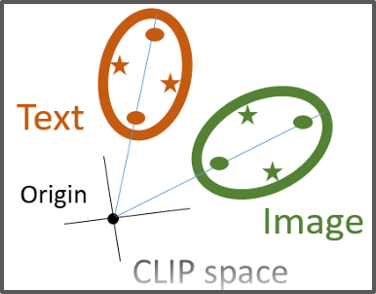
Image and text features occupy distinct, shifted ellipsoid shells in the raw CLIP space; their separability explains the modality gap while their offset from the origin explains the Narrow Cone Effect.
Conformity ≈ Mean-Similarity
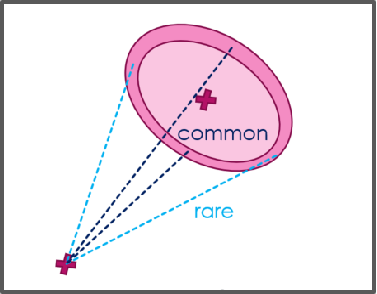
A sample's conformity—the average cosine similarity to all others—can be estimated by its cosine similarity to the modality mean.
Optimal Convergence
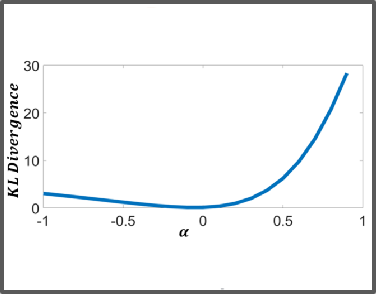
We found that in this position the alignment between the conformity distribution of text and images is optimal.
Practical Implications
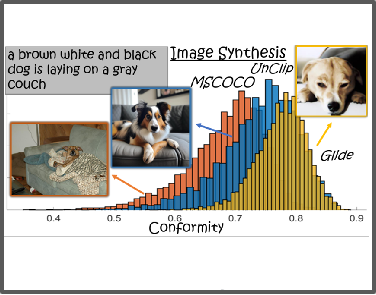
Understanding this geometry motivates simple diagnostics and improved alignment methods in downstream tasks.
Presentation
5 minutes presentation
Talk in Caltech Pietro Perona's Lab (one-hour)
Follow-up Work
Whitened CLIP as a Likelihood Surrogate of Images and Captions (ICML 25)

Our follow-up ICML 2025 paper analyzes CLIP in a probabilistic manner, focusing on image and text likelihood estimation. This reliable likelihood estimation enables zero-shot classification of AI-generated images.
5 minutes Presentation
INFONce Induces Gaussian Distribution (ICLR 26 Oral)
Our follow-up ICLR 2026 Oral paper show that method trained based on INFONce loss are inducing Gaussian distribution on the latent space under several reasonable assumptions
General and Domain-Specific Zero-shot Detection of Generated Images via Conditional Likelihood (WACV 26)
Roy's follow-up work with Fujitsu is adapting the log-likelihood estimation obtained from CLIP to custom datasets.
BibTeX
@inproceedings{levi2025double,
title={The Double-Ellipsoid Geometry of CLIP},
author={Levi, Meir Yossef and Gilboa, Guy},
booktitle={International Conference on Machine Learning},
year={2025}
}